强化学习简介:
- 什么是强化学习、
强化学习是计算机科学,经济学,数学,工程学,神经科学,心理学等多学科的交叉学科,可以被认为是机器学习独立于supervised learning与unsupervised learning之外的一个独立的分支。
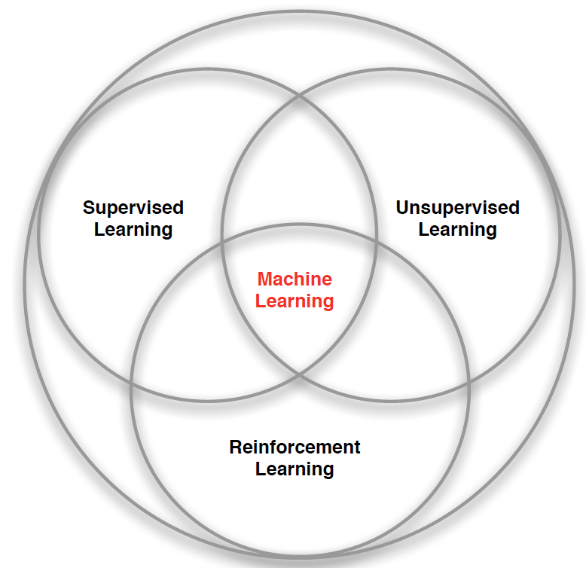
强化学习是一种基于不断试错的方法,可以被描述为agent不断地面对和学习随机环境,并作出相应的连续决定的一个过程。
现在,强化学习已经被用于许多领域,比如我们熟知的AlphaGo,它也可以被应用于量化金融领域,比如优化投资组合,或优化交易执行等方向。
不同于传统的机器学习,强化学习并不存在一个明确定义的supervisor,其所获得的反馈也在时间维度上存在滞后性,但正基于这样的特点,强化学习可以很好的处理具有时间序列性的问题,agent的行为会影响到其之后的数据输入。
2.强化学习的基本组成部分
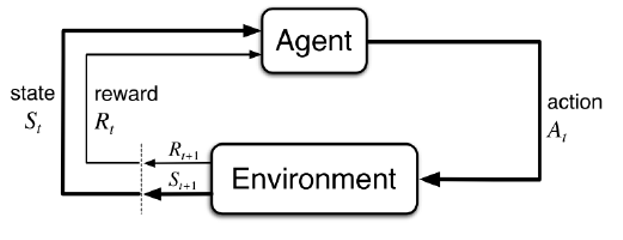
强化学习可以认为是agent与environment的交互问题。每一次的交互从agent收到上一个时间步的reward与当前时间步的state开始,agent依据policy或不依据policy做出相应的action,作用于environment,environment根据action及其自身的参数,得到reward和下一个state。
其中,reward是一个数值性的信号,定义agent在当前时间步action的好坏,而我们认为强化学习的最终目的为最大化预期收益总和。State则为用于决定之后发生事件的信息组合。
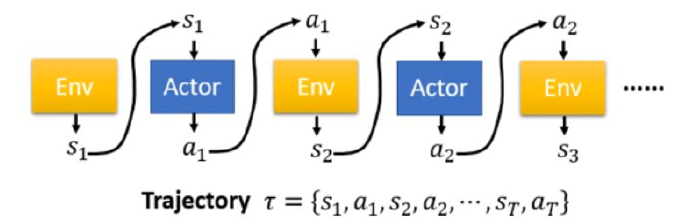
我们可以记录下上述state,action的循环过程,整一个过程被称为一个trajectory。
对于以θ为参数的agent,我们可以计算出任意一种trajectory发生的概率,即:
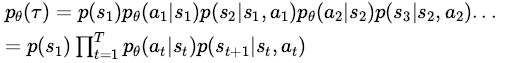
3.强化学习常用术语
- Policy:是agent的行为方式,是从state到action的一种映射。
- Value Function:是对于访问至某一state后,未来reward的预期,可以被看作是一个state的好坏。即:
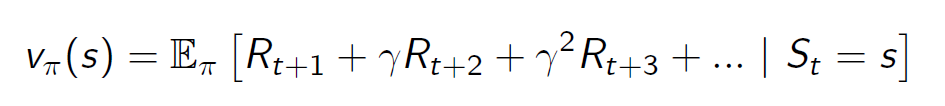
- Q Function: 与value function相似,反映了agent在访问state s并采取action a之后的预期未来reward,即:
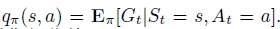
Model: model 预测了environment的行为方式,包括在state s下采取action a,获得不同reward的probability distribution,或行进到下一state s’的probability distribution: 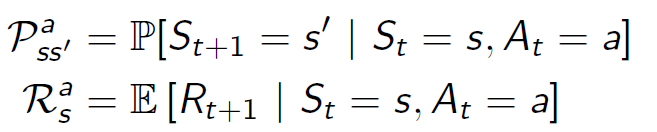
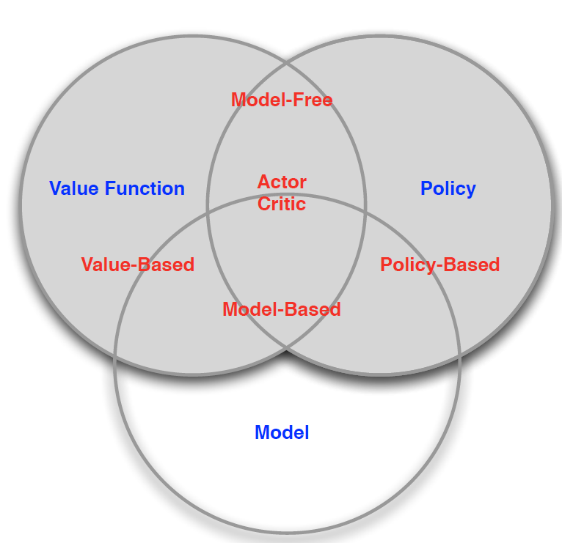
基于以上,我们可以将不同的强化学习算法,依据是否存在model,或者关注于policy还是value进行学习,分为不同的category:
ARS算法介绍:
ARS算法是基于BRS算法的一个改进算法。
- BRS算法:

- ARS算法:


其中三个改进的原因分别是:
1)不同状态下的变动范围是不同的,为了保证每个状态的变换范围相对一致,进行mean-std filter
2)随着iteration 的提高,reward的扰动也随之增大,除以reward的方差以保证步长稳定,更新所得的结果更加可控
3)由于空间的复杂性使收敛速度较慢,仅取扰动变化最大的几个方向进行更新会加快收敛速度。
3.实验结果
作者使用ARS算法进行了MuJoCo Task实验。
文章进行了几个维度的对比:
1. 到达一定的reward时所需的episode数量:
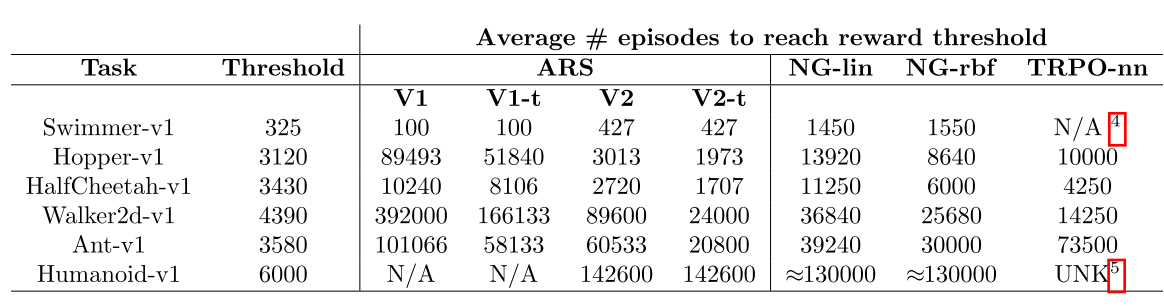
2. 同样的时间下不同起始点达到的平均reward:
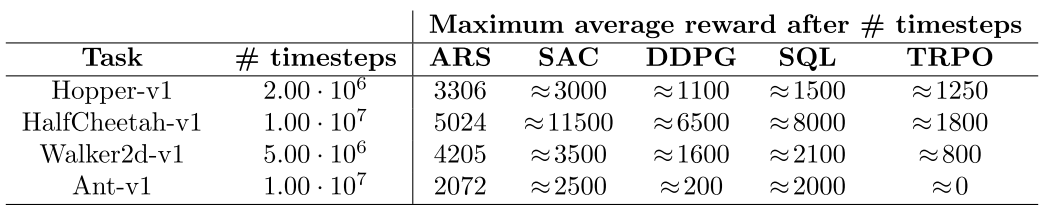
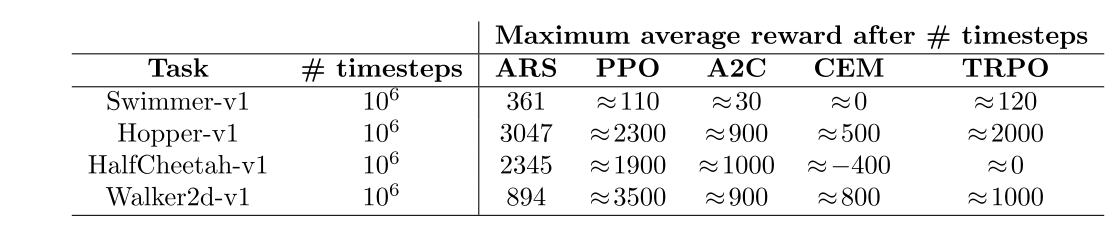 3. 足够长的时间下达到的最多的reward:
3. 足够长的时间下达到的最多的reward:
4.总结:
ARS在BRS的基础上进行了三个维度的改进,在结果上使用线性的模型达到了近似于复杂模型的效果,同时在速度上也有优势。在交易中,对于参数的选取可以通过ARS快速的找到局部最优。
5.应用
我们将ARS应用于模型的调参,基于不同的时间步下state差异,并根据前期的action,动态调整当前时间步下模型的参数,以达到最大预期收益。
References
Mania, H., Aurelia Guy, G., & Benjamin, R. (2018). Simple random search provides a competitive approach to reinforcement learning.